Students I've been fortunate to mentor and learn from:
At UW:
Aotian Zheng,
Bahaa Alattar,
Wei-Chieh (Winston) Sun,
Aman Tiwary,
Masa Nakura-Fan,
Soofiyan Atar,
Griffin Golias,
Gantcho Dimitrov,
Ryan Ching,
Jason Xie,
Peter Michael,
Rinav Kasthuri, and
Sophia He
At BU IVC/AIR:
Recent Projects
Tell Me What to Track
AI City Challenge 2021, AI City Challenge 2022
 |
Milind Naphade, Shuo Wang, David C. Anastasiu, Zheng Tang, Ming-Ching Chang, Yue Yao, Liang Zheng, Mohammed Shaiqur Rahman, Archana Venkatachalapathy, Anuj Sharma, Qi Feng, Vitaly Ablavsky, Stan Sclaroff, Pranamesh Chakraborty, Alice Li, Shangru Li, and Rama Chellappa, “The 6th AI City Challenge,” In Proc. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, 2022. [PDF]
Milind Naphade, Shuo Wang, David C. Anastasiu, Zheng Tang, Ming-Ching Chang, Xiaodong Yang, Yue Yao, Liang Zheng, Pranamesh Chakraborty, Christian E. Lopez, Anuj Sharma, Qi Feng, Vitaly Ablavsky, and Stan Sclaroff, “The 5th AI City Challenge,” In Proc. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, 2021.
[PDF] |
Siamese Natural Language Tracker
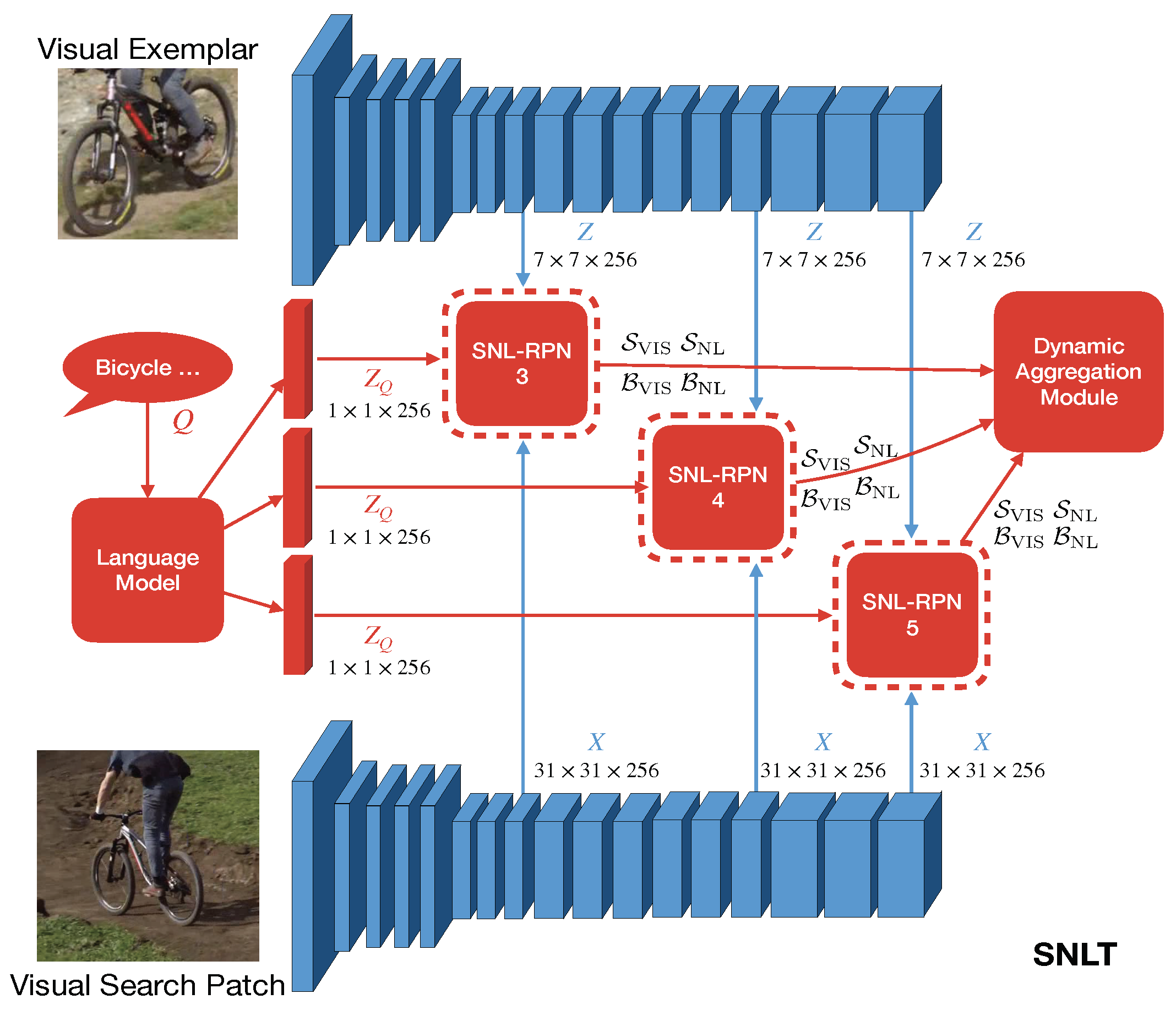 |
Qi Feng, Vitaly Ablavsky, Qinxun Bai, and Stan Sclaroff, “Siamese Natural Language Tracker: Tracking by Natural Language Descriptions with Siamese Trackers,” In Proc. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021. [oral]
[PDF] |
Robust Visual Object Tracking with Natural Language Region Proposal Network
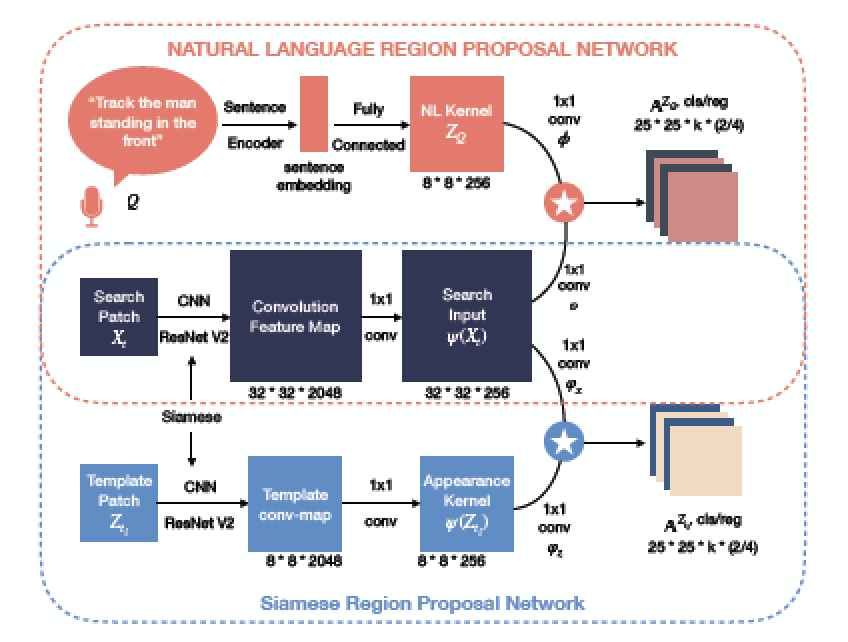 |
Qi Feng, Vitaly Ablavsky, Qinxun Bai, and Stan Sclaroff,
“Robust Visual Object Tracking with Natural Language
Region Proposal Network,” December 2019
[PDF] |
Real-time Visual Object Tracking with Natural Language Description
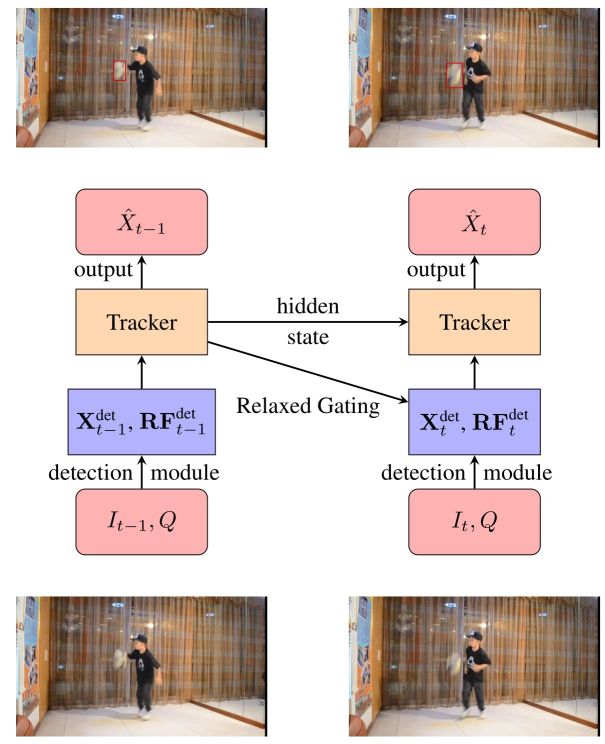 |
Qi Feng, Vitaly Ablavsky, Qinxun Bai, Guorong Li, and Stan Sclaroff,
“Real-time Visual Object Tracking with Natural Language Description,”
In Proc. IEEE Winter Conference on Applications of Computer Vision (WACV), 2020.
[PDF]
|
DMCL: Distillation Multiple Choice Learning for Multimodal Action Recognition
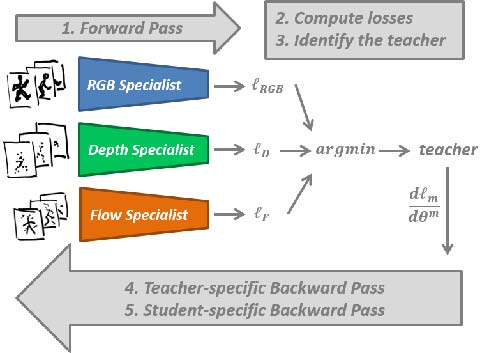 |
We address the problem of learning an
ensemble of specialist networks using multimodal data, while
considering the realistic and challenging scenario of possible
missing modalities at test time. Our goal is to leverage the
complementary information of multiple modalities to the benefit of
the ensemble and each individual network. We introduce a novel
Distillation Multiple Choice Learning framework for multimodal
data, where different modality networks learn in a cooperative
setting from scratch, strengthening one another.
[arXiv:1912.10982] |
Leveraging Affect Transfer Learning for Behavior Prediction in an Intelligent Tutoring System
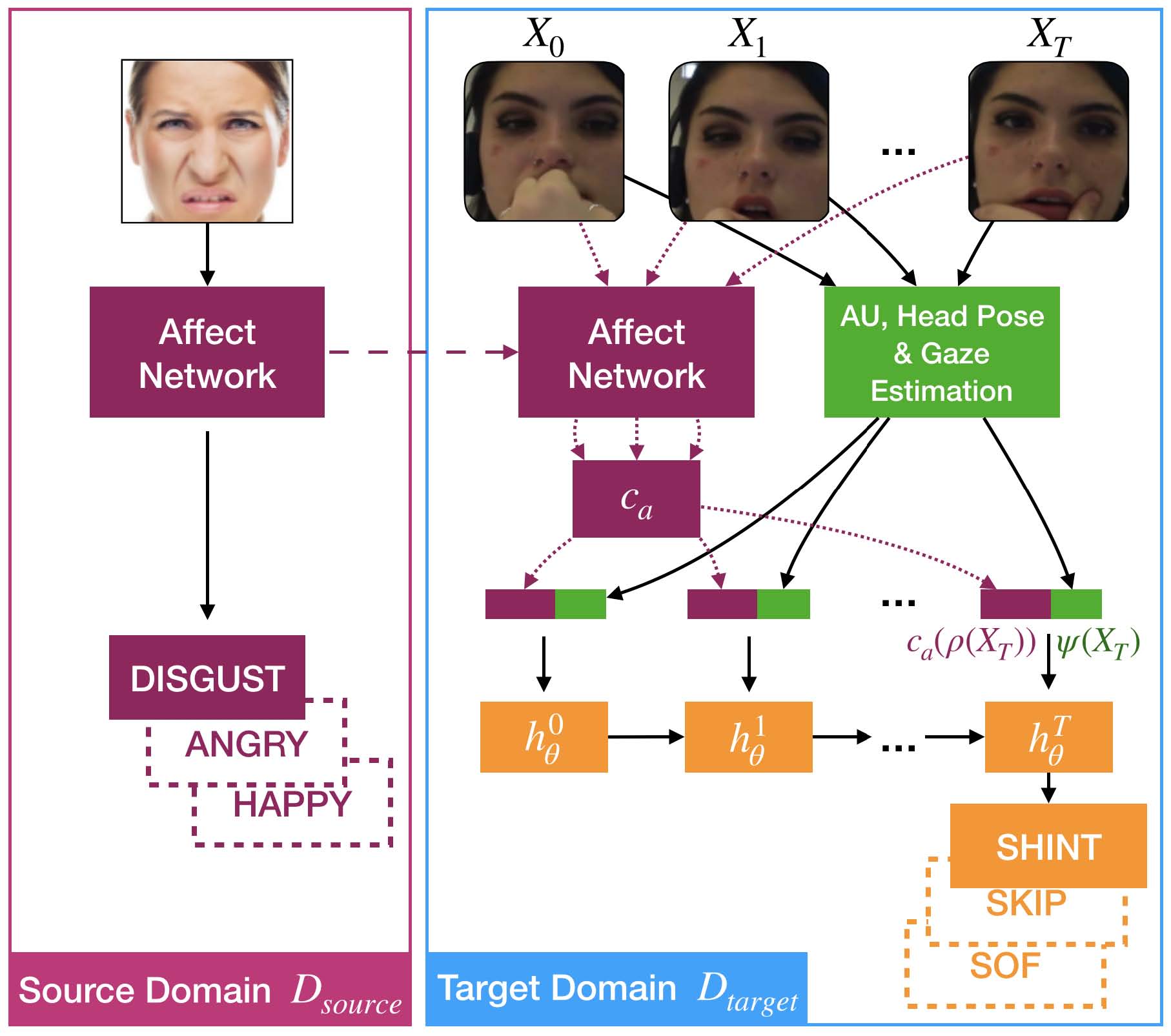 |
We set out to improve prediction of
student learning outcome via interventions in the context of an
intelligent tutoring system (ITS). Specifically, we want to
predict the outcome of a student answering a problem in an ITS
from a video feed by analyzing their face and gestures. For this,
we present a novel transfer-learning facial-affect representation
and a user-personalized training scheme that unlocks the potential
of this representation.
[arXiv:2002.05242] |
Learning to Separate: Detecting Heavily-Occluded Objects in Urban Scenes
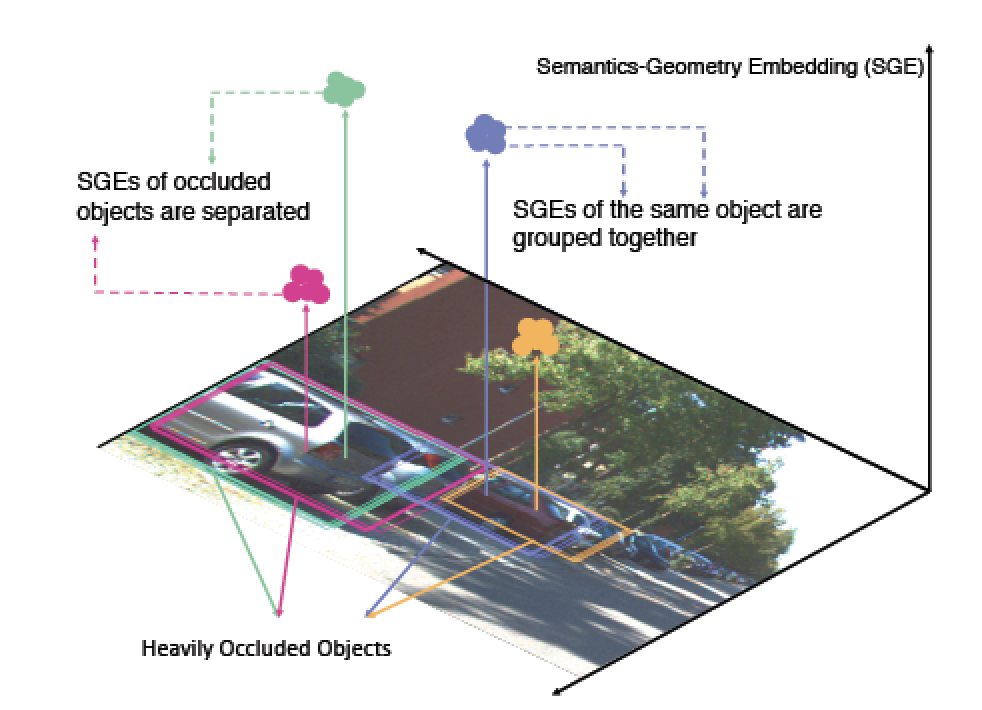 |
In the past decade,
deep-learning-based visual object detection has received a
significant amount of attention, but cases when heavy intra-class
occlusions occur remain a challenge. In this work, we propose a
novel Non-Maximum Suppression (NMS) algorithm that dramatically
improves the detection recall while maintaining high precision in
scenes with heavy occlusions. Our NMS algorithm is derived from a
novel embedding mechanism, in which the semantic and geometric
features of the detected boxes are jointly exploited.
[ECCV 2020 paper] |
DIPNet: Dynamic Identity Propagation Network for Video Object Segmentation
 |
We propose a Dynamic Identity Propagation Network (DIP-
Net) that adaptively propagates and accurately segments
the video objects over time. To achieve this, DIPNet dis-
entangles the VOS task at each time step into a dynamic
propagation phase and a spatial segmentation phase. The
former utilizes a novel identity representation to adaptively
propagate objects’ reference information over time, which
enhances the robustness to video objects’ temporal varia-
tions. The latter uses the propagated information to tackle
the object segmentation as an easier static image prob-
lem that can be optimized via slight fine-tuning on the first
frame, thus reducing the computational cost.
[WACV 2020 paper]
|
Cost-Aware Fine-Grained Recognition for IoTs Based on Sequential Fixations
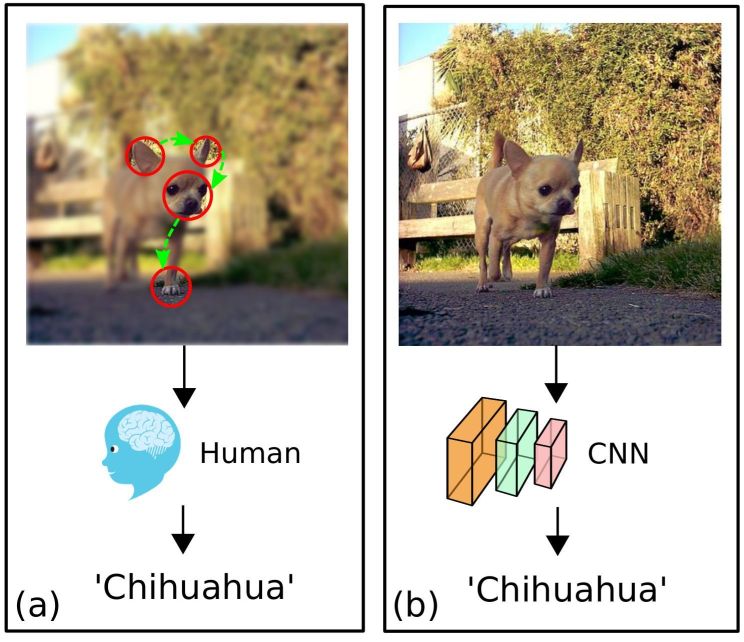 |
We consider the problem of
fine-grained classification on an edge camera device that has
limited power. The edge device must sparingly interact with the
cloud to minimize communication bits to conserve power, and the
cloud upon receiving the edge inputs returns a classification
label. To deal with fine-grained classification, we adopt the
perspective of sequential fixation with a foveated field-of-view
to model cloud-edge interactions. We propose a novel
deep-reinforcement-learning-based model, DRIFT, that sequentially
generates and recognizes mixed-acuity images. We train a
foveation actor network with a novel Deep Deterministic Policy
Gradient by Conditioned Critic and Coaching (DDPGC3) algorithm.
[ICCV 2019 paper] |
Take your eyes off the ball: tracking the invisible in team sports
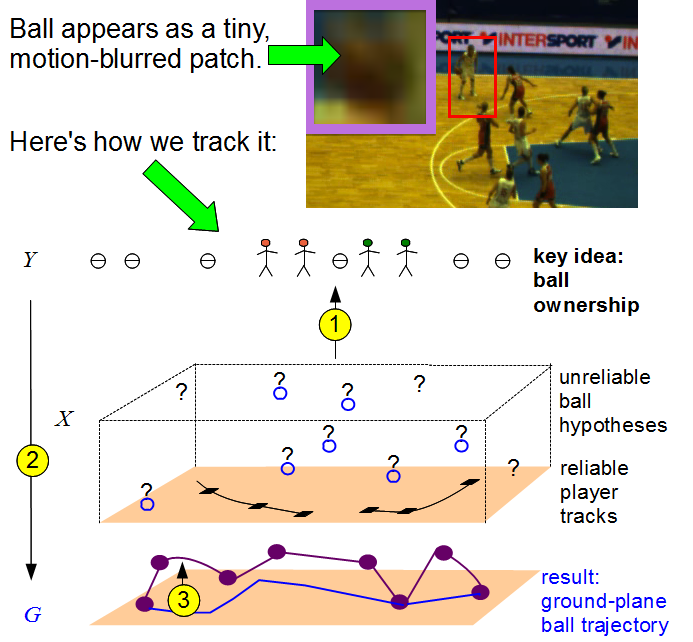 | Accurate video-based ball tracking in team sports is
important for automated game analysis, and has proven very
difficult because the ball is often occluded by the players. We
propose a novel approach to addressing this issue by formulating
the tracking in terms of deciding which player, if any, owns the
ball at any given time. This is very different from standard
approaches that first attempt to track the ball and only afterwards
assign ownership. We show that our method achieves a significant
increase in accuracy over such approaches on long basketball and soccer sequences. [CVIU
2014
]
[example
videos]
Missed our CVPR 2013 demo? Play basketball roulette here!
Missed CVPR 2016? See some cool follow-on work on Ball Tracking in Team Sports from the CVLab at EPFL.
Missed the 2018 World Cup? Test your powers of detection against futbol ground-truth here (no training required!)
|
Learning parameterized histogram kernels on the simplex manifold
for image and action classification
 | State-of-the-art image and
action classification systems often employ vocabulary-based
representations. The classification accuracy achieved with such
vocabulary-based representations depends significantly on the chosen
histogram distance. In particular, when the decision function is a
support-vector-machine (SVM), the classification accuracy depends on
the chosen histogram kernel. We learn parameters of histogram kernels
so that the SVM accuracy is improved. This is accomplished by
simultaneously maximizing the SVM's geometric margin and minimizing
an estimate of its generalization error.
[ICCV 2011
paper][code]
|
Layers of graphical models for tracking partially-occluded objects
 | We propose a representation for scenes containing
relocatable objects that can cause partial occlusions of people in a
camera's field of view. In this representation, called a graphical model layer,
a person's motion in the ground plane is defined as a first-order
Markov process on activity zones, while image evidence is aggregated
in 2D observation regions that are depth-ordered with respect to the
occlusion mask of the relocatable object. The effectiveness of our
scene representation is demonstrated on challenging parking-lot
surveillance scenarios. [T-PAMI 2011 paper]
, datasets]
[CVPR2008 paper] |
Learning a familty of detectors via multiplicative kernels
 | Object detection is challenging
when the object class exhibits large within-class variations. In this
work, we show that foreground-background classification (detection)
and within-class classification of the foreground class (pose
estimation) can be jointly learned in a multiplicative form of two
kernel functions. Model training is accomplished via standard SVM
learning. Our approach compares favorably to existing methods on hand
and vehicle detection tasks. [T-PAMI 2011 paper] [CVPR 2008 paper] [CVPR 2007 paper]
|
Document image analysis and enhancement for multi-lingual OCR
 | Modern optical character
recognition (OCR) engines achieve remarkable accuracy on clean
document images but tend to perform poorly when presented with
degraded documents or documents captured with hand-held devices. The
problem is exacerbated for multilingual OCR engines. We proposed an
approach for automated script identification for degraded documents
and for an automatic correction of perspective warp. [ICDAR 2005 paper] [ICDAR 2003 paper] |
Tracking small vessels in littoral zones
 | In water-based scenarios, waves
caused by wind or by moving vessels (wakes) form highly correlated
moving patterns that confuse traditional background analysis
models. In this work we introduce a framework that explicitly models
this type of background variation. The framework combines the output
of a statistical background model with localized optical flow analysis
to produce two motion maps. In the final stage we apply object-level
fusion to filter out moving regions that are most likely caused by
wave clutter. The resulting set of objects can now be handled by a
tracking algorithm. [ICIP 2003
paper] |
|